Kafka Architecture & Internal
This talks about the Apache Kafka Architecture, its components and the internal structure for Kafka for its components.
Why Kafka?
- Multiple producers
- Multiple consumers
- Disk based persistence
- Offline messaging
- Messaging replay
- Distributed
- Super Scalable
- Low-latency
- High volume
- Fault tolerance
- Real-time Processing
Apache Kafka Architecture
Single Cluster: Apache Kafka
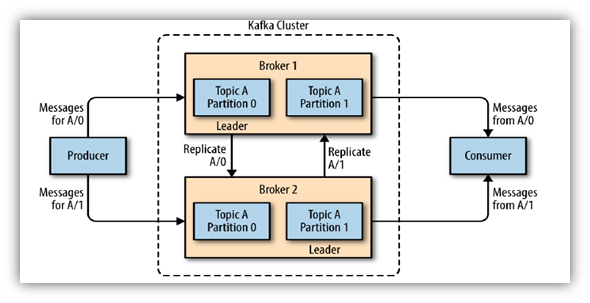
Components:
- Broker
- Producer
- Consumer
- Message
- Zookeeper
- Topic
Broker:
- Core component of Kafka messaging system
- Hosts the topic log and maintain the leader and follower for the partitions with coordination with Zookeeper
- Kafka cluster consists of one or more broker
- Maintains the replication of partition across the cluster
Producer:
- Publishes the message to a topic(s)
- Messages are appended to one of the topic
- It is one of the user of the Kafka cluster
- Kafka maintains the ordering of the message per partition but not the across the partition
Message:
- Kafka message consists of a array of bytes, addition to this has a optional metadata is called Key
- A custom key can be generated to store the message in a controlled way to the partition. Like message having a particular key is written to a specific partition.(key is hashed to get the partition number)
- Kafka can also write the message in batch mode, that can reduces the network round trip for each message. Batches are compressed while transportation over the network.
- Batch mode increases the throughput but decreases the latency, hence there is a trade-off between latency and throughput.
Consumer
- Subscriber of the messages from a topic
- One or more consumer can subscriber a topic from different partition, called consumer group
- Two consumer of the same consumer group CAN NOT subscribe the messages from the same partition
- Each consumer maintains the offset for subscribing partition
- A consumer can re-play the subscription of message by locating the already read offset of the partition of a topic
Topic:
- Can be considered like a folder in a file system
- Producers published the message to a topic and consumer consumes the message from here
- Message is appended to the topic
- Each message is published to the topic at a particular location named as offset. Means the position of message is identified by the offset number
- For each topic, the Kafka cluster maintains a partitioned log
- Each partition are hosted on a single server and can be replicated across a configurable number of servers for fault tolerance
- Each partition has one server which acts as the “leader” and zero or more servers which act as “followers”
- Kafka provides ordering of message per partition but not across the partition
- Topic naming convention
<root name space>.<product>.<product specific hierarchy>
<app type>.<app name>.<dataset name>.<stage of processing>
<app type>.<dataset name>.<data>Multi Cluster: Apache Kafka

Commercial Version: Confluent Kafka

Additional Components
- Development & Connectivity: Connectors, REST proxy, KSQL
- Data Compatibility: Schema Registry
- Enterprise Operation: Replicator, Connector, Auto data balance
- Management and Monitoring: Control Centre, Security
Why is Kafka super fast?
Persistence
- Kafka uses the file system for storing and caching messages
- In Recent time the performance of disk has drastically increased
- A modern operating system provides read-ahead and write-behind techniques that prefetch data in large block multiples and group smaller logical writes into large physical writes
- Disk supports as significantly increased in use of main memory for disk caching. A modern OS will happily divert all free memory to disk caching with little performance penalty when the memory is reclaimed
Batching
- Parallel write and read by design
- Batching is main buster for the transfer of data from producer to broker or from broker to file system.
To understand the impact of send file, it is important to understand the common data path for transfer of data from file to socket:
- The operating system reads data from the disk into page cache in kernel space
- The application reads the data from kernel space into a user-space buffer
- The application writes the data back into kernel space into a socket buffer
- The operating system copies the data from the socket buffer to the NIC buffer where it is sent over the network
This is clearly inefficient, there are four copies and two system calls.
- Using the zero-copy optimization above, data is copied into page cache exactly once and reused on each consumption instead of being stored in memory and copied out to user-space every time it is read. This allows messages to be consumed at a rate that approaches the limit of the network connection
End-to-end Batch Compression
Kafka writes the batch of messages in compressed form and will remain compressed in the log and will only be decompressed by the consumer.
Kafka supports GZIP, Snappy, LZ4 and ZStandard compression protocols.
Push vs. pull
- Messaging system can have pull or push
Push
- Consumer can be overwhelmed by flooded message by producer
- Difficulties dealing with diverse consumers.
Pull
- Consumer can pull the record as per capacity from broker
- Batching is created for pulling the data as per consumer
- Kafka can pull the batch on interval of time fix or the required byte size
Log Compaction
- Log compaction ensures that Kafka will always retain at least the last known value for each message key within the log of data for a single topic partition.
- It addresses use cases and scenarios such as restoring state after application crashes or system failure, or reloading caches after application restarts during operational maintenance
- Log compaction is a mechanism to give finer-grained per-record retention, rather than the coarser-grained time-based retention
- The idea is to selectively remove records where we have a more recent update with the same primary key.

Testing Kafka
Creating Topics
- Now create a topic with name “test.topic” with replication factor 1, in case one Kafka server is running(standalone setup).
- If you have a cluster with more than 1 Kafka server running, you can increase the replication-factor accordingly which will increase the data availability and act like a fault-tolerant system.
- Open a new command prompt in the location C:\kafka_2.11–0.9.0.0\bin\windows and type following command and hit enter.
kafka-topics.bat -- create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test.topicCreating a Producer
- Open a new command prompt in the location C:\kafka_2.11–0.9.0.0\bin\windows.
- To start a producer type the following command:
kafka-console-producer.bat — broker-list localhost:9092 --topic test.topic
Start Consumer
- Again open a new command prompt in the same location as C:\kafka_2.11–0.9.0.0\bin\windows
- Now start a consumer by typing the following command:
kafka-console-consumer.bat — zookeeper localhost:2181 — topic test.topic
- Now you run the producer and consumer on two command window
- Type anything in the producer command prompt and press Enter, and you should be able to see the message in the other consumer command prompt
Some Other Useful Kafka Commands
- List Topics:
kafka-topics.bat --list --zookeeper localhost:2181- Describe Topic
kafka-topics.bat --describe --zookeeper localhost:2181 --topic [Topic Name]- Read messages from beginning
kafka-console-consumer.bat --zookeeper localhost:2181 --topic [Topic Name] --from-beginning
- Delete Topic
kafka-run-class.bat kafka.admin.TopicCommand --delete --topic [topic_to_delete] --zookeeper localhost:2181
Data Directory
Suppose we have set the data directory as tmp and created a topic called invoice with 5 partition. The anatomy of data directory will looks like as below.

Further anatomy of the topic invoice will looks like as below.

File Types:
- index
- log
- timeindex